In this project, we explored the use of adversarial training to defend against adversarial patch attacks on image classification networks. Unlike imperceptible attacks, adversarial patches involve clearly visible contiguous perturbations covering a small area of an image that cause the network to misclassify the image. They are easier to use in practice since the patch can be printed out as a sticker and can be placed on an object or a the camera lens, causing subsequent automated analysis of the image to fail. An example where such an attack could be critical is the classification of stop signs by autonomous vehicles.
Approach
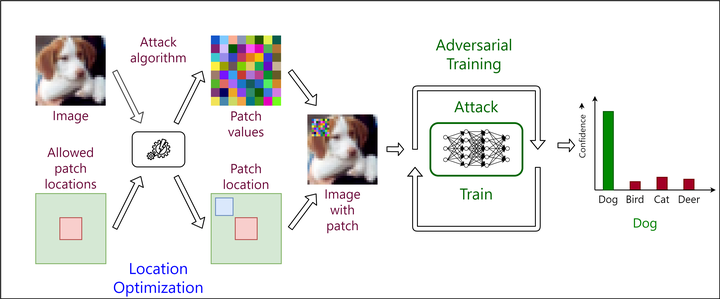
Adversarial training improves a network’s robustness to adversarial examples by training it to correctly classify them. The training process of the network then involves alternating between training the network to classify against strong adversarial examples, and generating strong adversarial examples that can fool the current iteration of the network. Consequently, it is desirable to using a stronger attack to generate adversarial examples would result in a more robust network.
To defend against adversarial patches, we make the following choices on the nature of the patches to get a strong attack, and then perform adversarial training against it:
- Image-Specific: A separate patch is generated for each image, which is more effective against that particular image as compared to a universal patch intended to work on any image of that class.
- Untargeted: The patch only needs to cause the network to misclassify the image, but does not require it to classify it as any specific alternative class. This is done by optimizing for patch values that maximize the network’s classification loss for each image.
- Location-Optimized: The patch values and location are jointly optimized. We use two location optimization strategies to approximately find the optimal location of the image to place the patch that results in the strongest attack.
Experimental Results
We evaluate on the CIFAR10 and GTSRB datasets on the ResNet-20 architecture. On a high level, the experimental evaluation shows that:
- Location optimization makes the attack stronger.
- Adversarial training against adversarial patches improves network robustness. Adversarial training against location-optimized adversarial patches improves it further.
- The accuracy of the network against non-adversarial examples does not decrease.
- Visualization of successful attack suggests that adversarial training reduces the area on an image where an adversarial patch attack can succeed.
Further details can be found in the paper. A visualization of the approach can be found in the slides.