Fast Dawid-Skene (FDS) is an algorithm for crowdsourced vote aggregation. Given a dataset with labels for each data point annotated by a group of people (the crowd), the algorithm aggregates the responses to predict the true labels. Fast Dawid-Skene is based on the well-known Dawid-Skene (DS) algorithm, and improves upon it by providing aggregated labels in much fewer iterations with comparable accuracy. This allows it to be usable for real-time, online applications. While the algorithm has been shown to be useful for sentiment classification, it can also be applied to any other domain.
Motivation
The motivation for the problem stems from the need for large, labeled, training datasets for effective supervised learning, which can often be difficult to obtain. Moreover, in today’s world, problems such as sentiment classification need quick, real-time decisions, such as identifying hate speech on social media platforms. Such problems could be solved by obtaining labels (out of a set of labels) from viewers of such platforms, and aggregating them to make decisions.
Existing Approaches
One of the simplest vote aggregation algorithms is the Majority Voting algorithm. In this algorithm, the aggregated label for each data point is simply the label that appears most among the crowd annotations for that data point. However, this fails to take into account potentially useful information: the reliabilities of the annotators vary. Some of the annotators might be domain experts, with very high accuracy, while some might have answered randomly. Others might not be sufficiently trained to accurately provide a label, or might be spammers. The majority voting algorithm does not take these differences into account. It would be useful to identify the experts and give their labels more weight during aggregation.
Many other aggregation algorithms have been proposed, that overcome the shortcomings of majority voting. One of the well-known approaches, and among the state-of-the-art, is the Dawid-Skene algorithm. It is an EM-based algorithm, which in the E-step estimates the proposed true labels given parameters, and in the M-step estimates parameters maximizing the likelihood. This results in expert annotators getting more weight. This algorithm has been effective, and has become the baseline on which newer approaches are based. However, we found that the convergence of Dawid-Skene would often be slow, which would prevent it from being usable for real-time applications. To overcome this, we proposed an algorithm based on the Dawid-Skene approach, called Fast Dawid-Skene (FDS), that could provide comparable accuracy to Dawid-Skene in much fewer iterations.
Fast Dawid-Skene: Approach
The key idea of Fast Dawid-Skene is to binarize the proposed labels at each EM iteration. In Dawid-Skene, the proposed answer sheet at each iteration is a probability distribution. Our approach fixes the labels to be 0 or 1 at each step. The idea can be perceived as a ‘hard’ version of Dawid-Skene. We then showed theoretical convergence guarantees for our approach. We also proposed a few variants of our approach:
- Hybrid algorithm: It was observed that the while Fast Dawid-Skene would quickly converge, the likelihood values attained by Dawid-Skene would be better, due to the use of softer marginals. To achieve the best of both worlds, the Hybrid variant starts with the Dawid-Skene algorithm, and switches to Fast-Dawid Skene after the sum of the absolute values of the differences of class marginals falls below a certain threshold. While this helped achieve better likelihood values, it did not necessarily perform better than FDS.
- Online Vote Aggregation: It is often the case that data is available in a stream, where newer data arrives with time. In such a situation, it would be expensive, wasteful, and perhaps prohibitive to repeat aggregation on the entire dataset from scratch. This variant of Fast Dawid-Skene allows using the information from past iterations to perform aggregation of new data points as they arrive.
- Multiple-Answer Correct setting: One of the assumptions made was that for any data point, only one label was the true label. This variant relaxes the assumption by allowing multiple true labels. This is done by interpreting each question-label pair as a binary classification problem, and then applying the Fast-Dawid Skene algorithm.
An example run of the Fast Dawid-Skene algorithm can be found here.
Experimental Evaluation
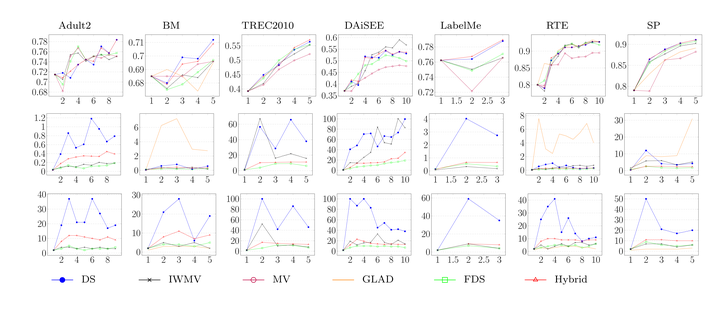
The algorithms were evaluated over seven datasets, most of them corresponding to sentiment analysis. They were compared against Dawid-Skene, and two other existing approaches: GLAD and IWMV. It was found that on most of the datasets, the Fast-Dawid Skene and the Hybrid algorithms had similar accuracies to Dawid-Skene. However, FDA converged up to 8x faster than DS on some datasets, and up to 6x faster than IWMV, which is reported to be a fast algorithm. As expected, the Hybrid algorithm converged to better likelihoods, but in more time, though it was still faster than DS and mostly faster than IWMV.
For online vote aggregation, FDS and Hybrid again converged faster than DS with similar accuracy. In the multiple-answer setting, FDS performed 7x better than DS, and outperformed previously reported state-of-the-art results on that setting.
Further details about the algorithm and the experimental results can be found in the paper.